ISC21 International Supercomputing Competition
Gains: This was my first time learning about Linux and high performance computing in depth. Prior to the competition, I didn’t even know basic Linux commands like cd, ls, and rm. However, I learned quickly during the event and acquired many valuable skills, such as understanding the purpose and source code of unfamiliar applications, analyzing their runtime performance, and tuning parallel parameters to reduce communication cost. Most importantly, I learned to embrace challenges and confidently acquire new knowledge.
About the competition
ISC used to be an offline competition, but due to COVID19, ISC 2021 was held remotely, and 13 teams need to complete a series of tasks on two shared computing clusters.
In competing, we are asked to run the following challenges: micro-benchmarks, including the HPL, HPCC and HPCG benchmark; challenging HPC applications, including the Weather Research and Forecasting (WRF) model, the GPAW atomic-scale quantum mechanical simulation model and the LAMMPS classical molecular dynamics code (which focuses on materials modeling), etc.
In this competition, I concentrated on running benchmarks and working with WRF. For the benchmarks, I carried out the tests and enhanced their performance through parameter tuning. Since my primary focus was on WRF, the following sections are all about it.
Background
WRF is a numerical weather prediction model, and is currently in operational use at National Centers for Environmental Prediction (NCEP) and other national meteorological centers.
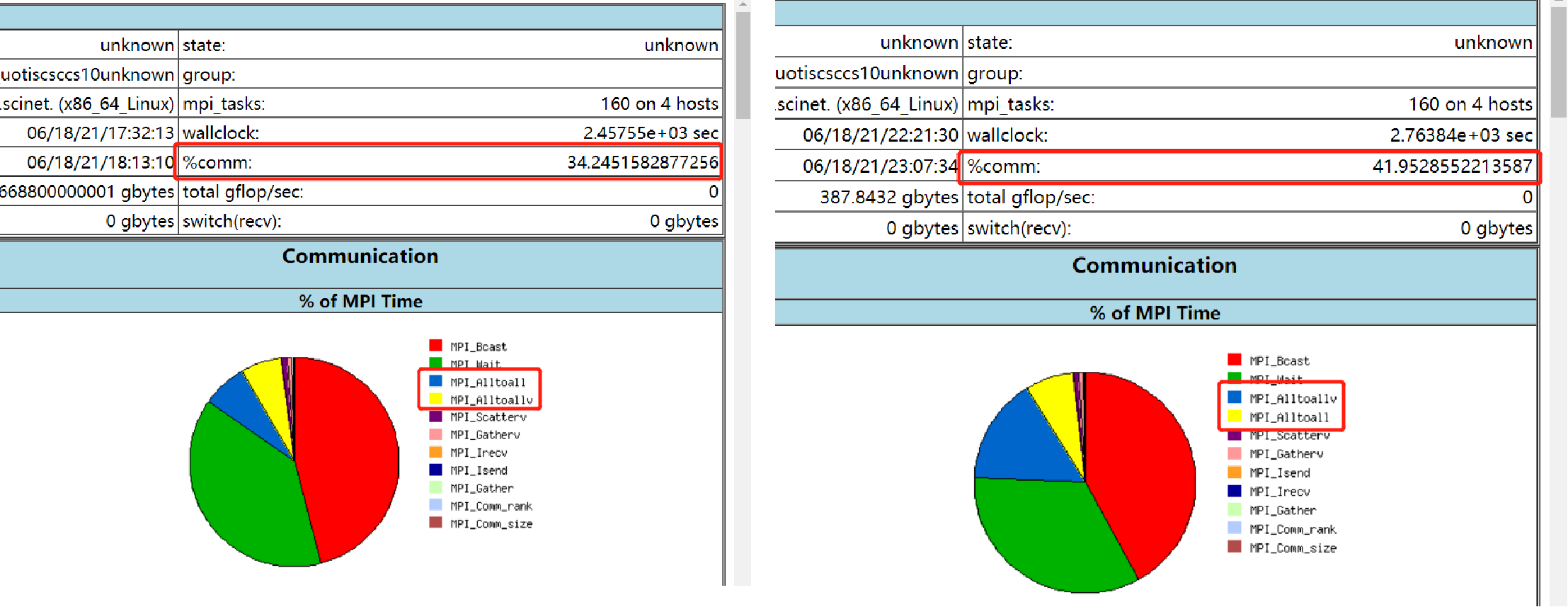
WRF can run parallelly, when MPI (process-level) and OpenMP (thread-level) are enabled. By adjusting parallel parameters, we can reduce communication between threads and processes, thereby improving the program’s running speed.

Strategies used and worked
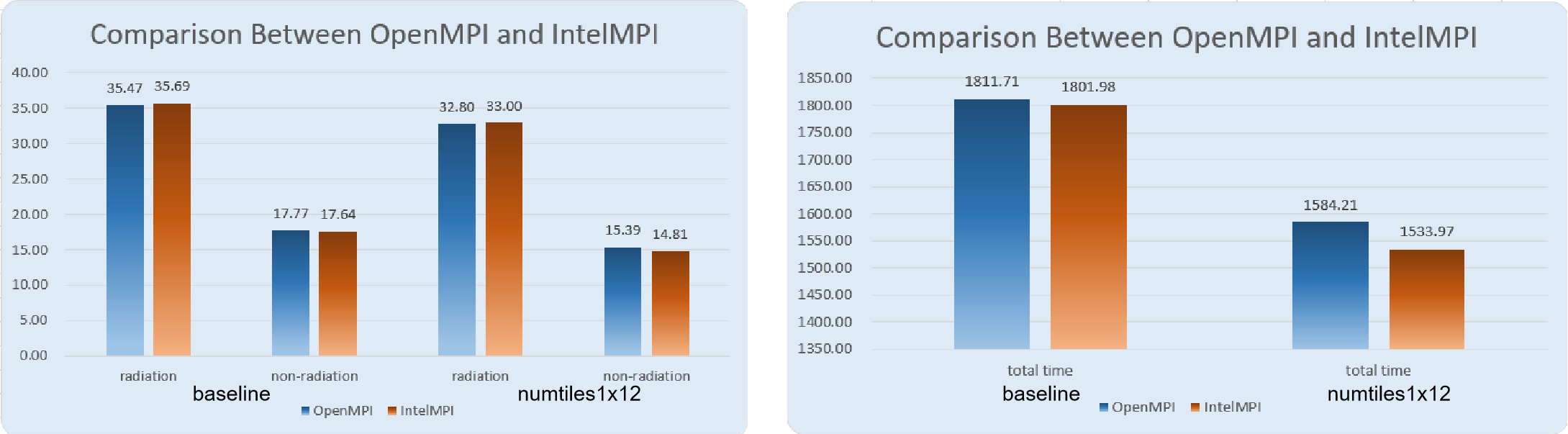
Change MPI Library
There are various implementations of MPI. The official installation guide uses OpenMPI, but IntelMPI ofter outperforms it. We tried both, and found that the latter worked better.
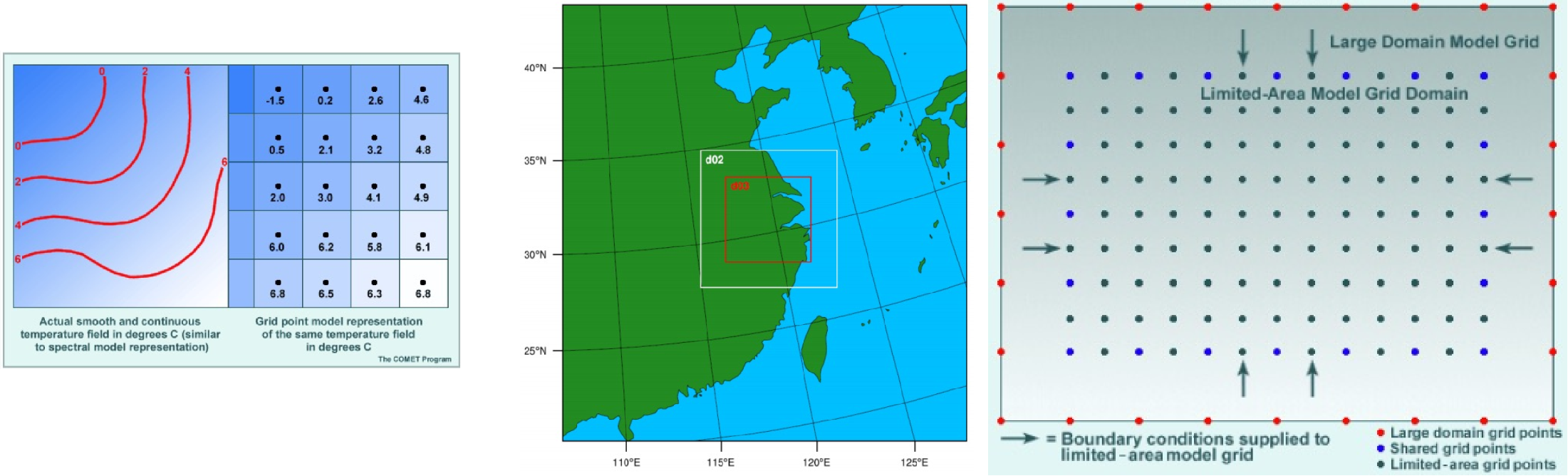
MPI process allocation strategy
We first tried different numbers of MPI processes in a rough manner, and then carefully experimented with various process allocation strategies (using the
numtilesandnprocparameters in the WRF configuration file). For a rectangular region on the map where we want to perform weather prediction, the WRF configuration file allows us to specify how many tiles to allocate along the x-axis and y-axis. Different allocation schemes result in different communication overhead.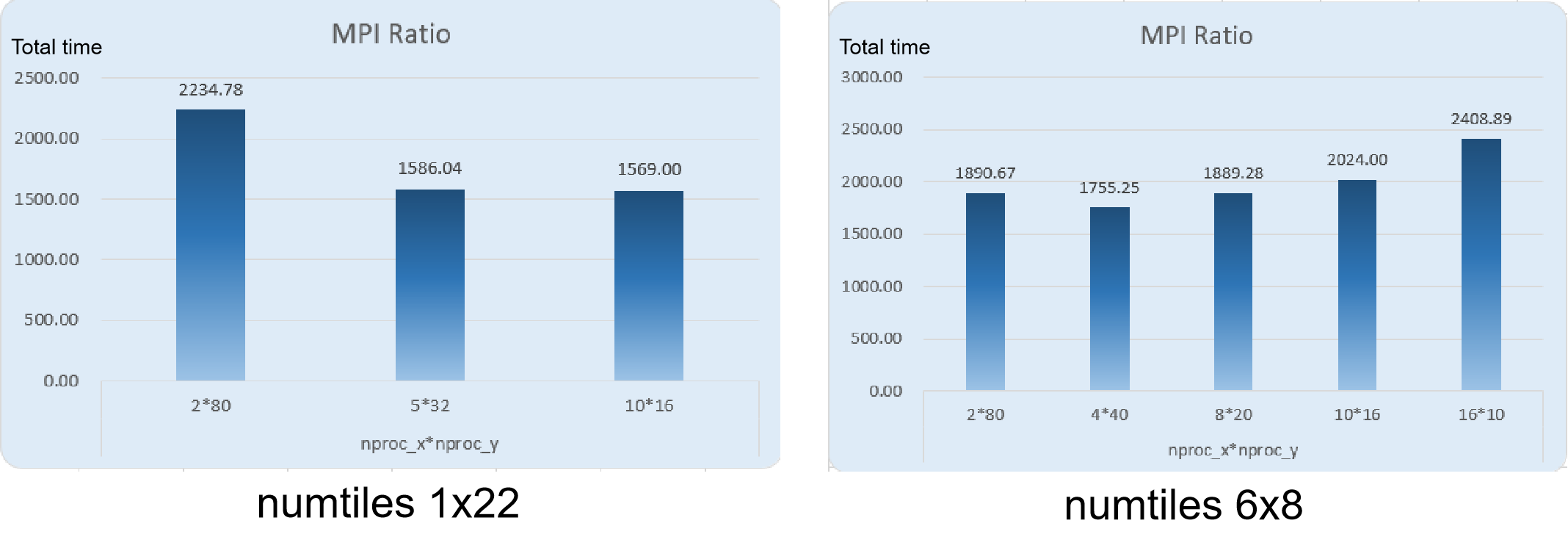
OpenMP process allocation patterns
We also tried different
numtilespatterns, and found that thin and long pattern worked the best (numtiles_x=1).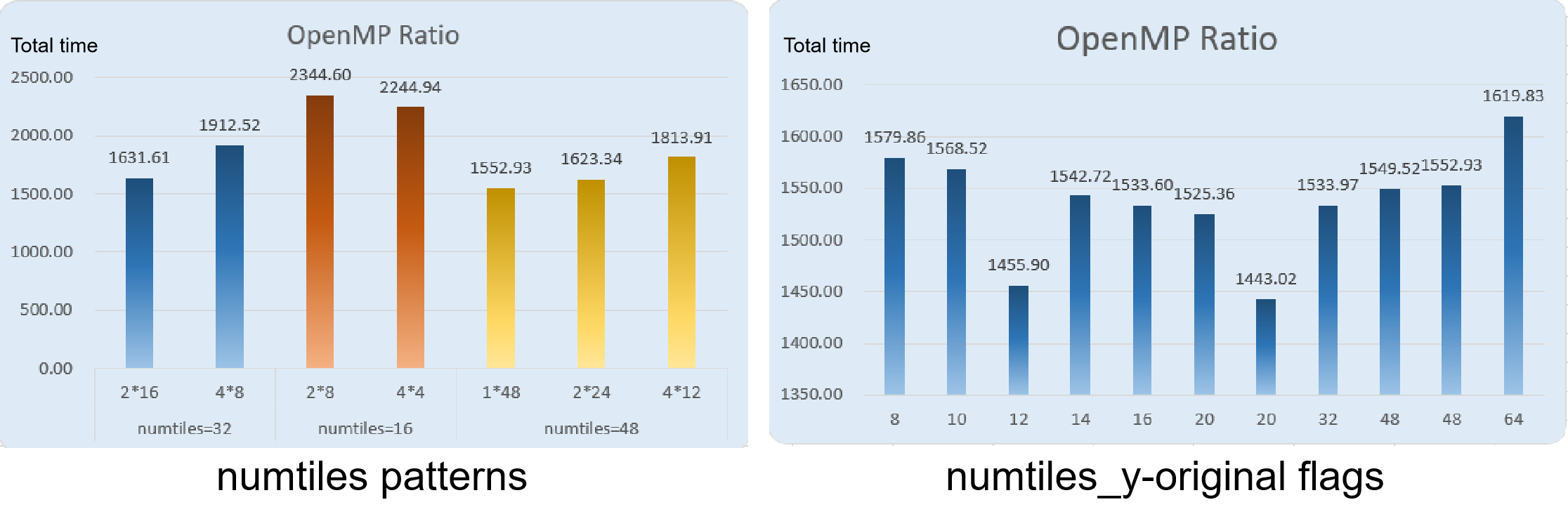
Tuning the WRF configuration file
We removed
-fp-model preciseflag in theconfigure.wrffile, and achieved better runtime, because it sacrificed some precision during the computation.Then we studied compiling flags of the compiler
ifort, and added useful flags-qopenmpand-fpp. The former flag enables the parallelizer to generate multi-threaded code based on OpenMP directives; and the latter runs the Fortran preprocessor on source files before compilation.At that time, he Intel HPC toolkit updated a new compiling flag called
AVX512, which is relavant to vector computation, and by default it wasAVX2. We tried both, and found thatAVX2worked better in our case.
Strategies explored but not worked
Install parallel version of the libraries
We installed
Pnetcdf,Parallel-I/Olibraries, enabledHDF5with parallel feature, and enabledNetCDFwithHDF5andPnetcdfsupport. These operations can reduce input and output time. But the competition didn’t compute I/O time, so this strategy didn’t help us in the competition.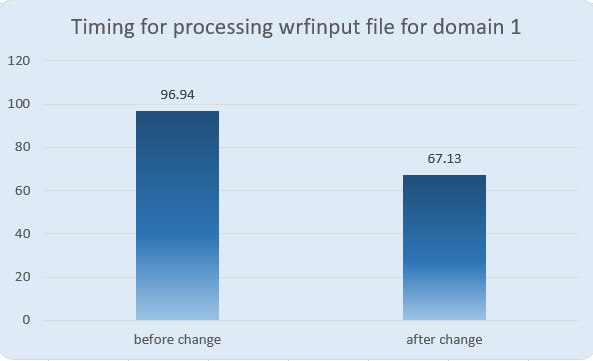
Improve MKL library
There are many FFT operations in WRF, to filter out noise in polar areas. We can reduce calls to
fftpack5by changing default MKL library to Intel MKL DFT interface. This may provide up to 3x speed up of simulation speed, ideally. However, in our experiments, changing MKL library worked differently on different HPC clusters, and it didn’t work well on the shared clusters during the competition.The reason of this uncertainty is: if we want to replace the library properly, we must change the code; besides, FFT is only used to filter out noise in polar areas, which is useless in our case (Southeast China).
Balance MPI communication
We tried to use a
rankfile(a definition only useful to OpenMPI) to balance MPI communication on nodes. We first got the communication amount between all the 160 ranks, and then regarded it as a graph and usedmetisto partition it. Then, we used the partitioned graph to generate a rankfile and ran WRF with it.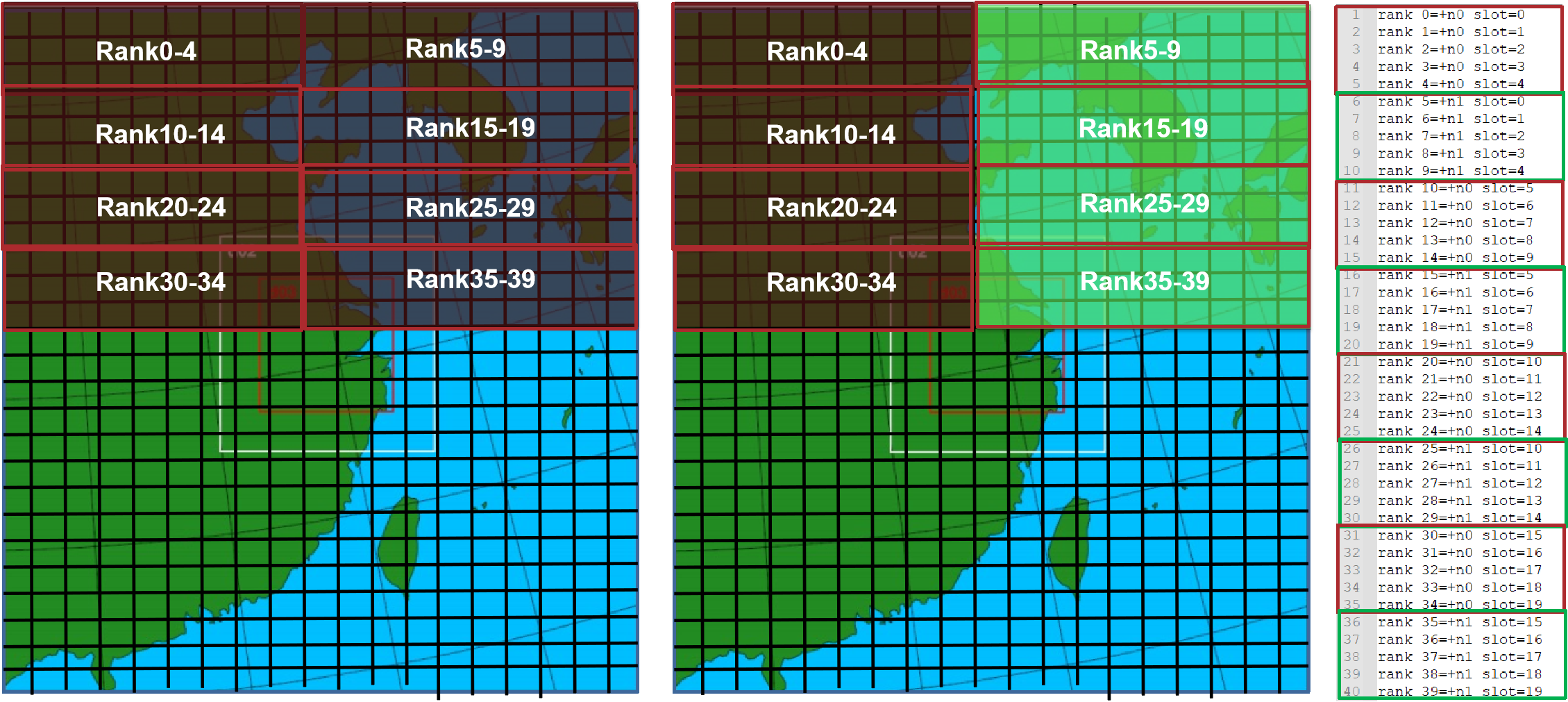
However, when we used
VTuneto analyse the performance of WRF, we found that the MPI functionMPI_Alltoallv()was more balanced when specifyingrankfile, but there was more communication in total, and thus more running time.