
Replica Server Placement in a Satellite Network
Finished in 2023
Authors: Zhiyuan He, Yi Xu*, Cheng Luo, Lili Qiu, Yuqing Yang
Motivation
Low Earth Orbit (LEO) satellites have low latency and wide coverage capabilities, and thus they have various applications on global connectivity. Our paper apply LEO satellites with Content Delivery Networks (CDN) for improving internet infrastructure, especially in remote regions.
Conventional CDNs rely on terrestrial networks and distributed data centers to cache and deliver content efficiently to users worldwide. However, these networks face challenges such as latency, limited coverage in remote areas, and high infrastructural costs. LEO satellite networks address these limitations by providing:
- Global coverage: LEO constellations ensure connectivity even in remote or rural locations.
- Low latency: With altitudes around 500–2000 km, LEO satellites offer much lower latency compared to GEO satellites.
- Frequency re-use: LEO satellites only see a small part of the Earth’s surface, and thus they are good for frequency re-use.
Challenges
Deploying CDN replicas in LEO satellite networks involves unique challenges:
- Dynamic topology: Satellites move quickly, and their coverage areas constantly change. When a LEO satellite moves out of range of terrestrial gateway and terminal, this satellite need to handover its content to next satellite.
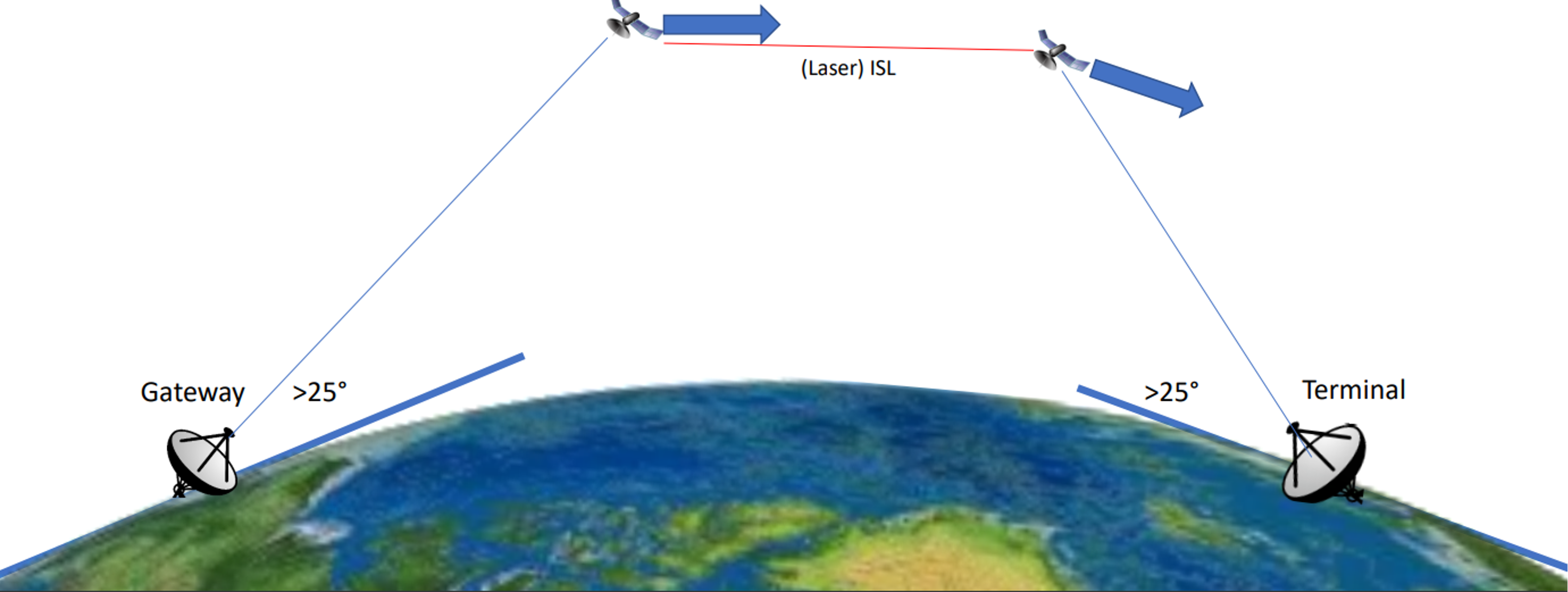
- Replica placement: Deciding where and when to place content replicas to optimize delivery.
- Client coverage: Ensuring every client can efficiently reach a content replica as satellites and users move.
Algorithms
This problem can be formalized as Facility Location Problem: Among all the LEO satellites, we choose and open several of them as facilities (CDN replicas). And the opened facilities have connection and handover cost when they are serving the users. Then, our goal is to minimize the sum of open cost and connection cost.
| Input: facilities and users | Facility location solution |
|---|---|
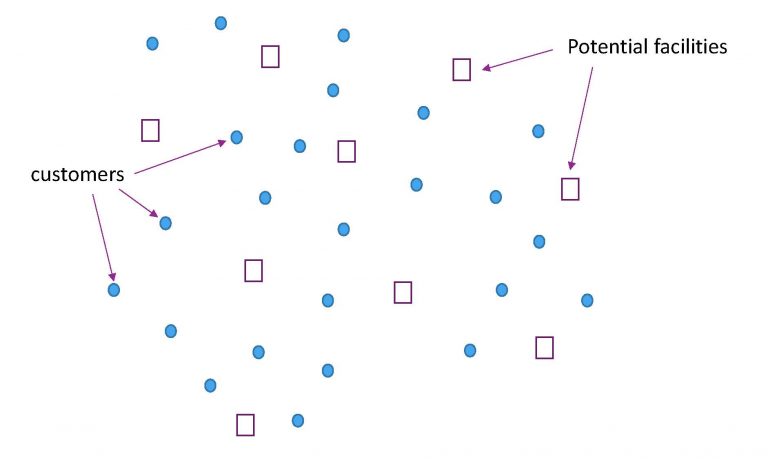 | 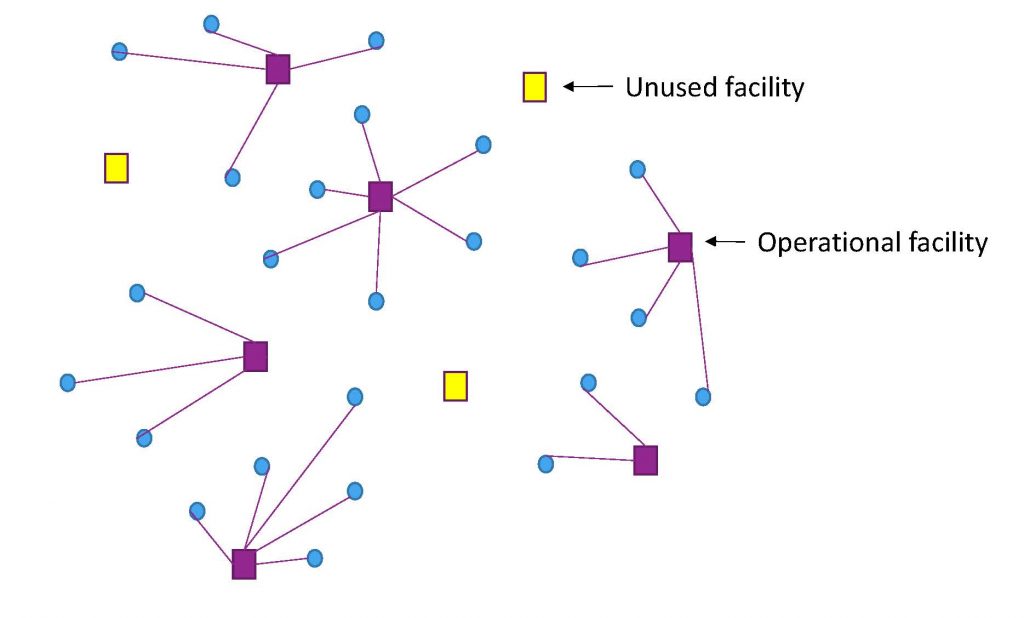 |
Greedy facility location algorithms
The original greedy algorithm runs as follows:
- Initialize opened facility set and assigned client set to be empty
- While there exists clients who are unassigned:
- Pick a facility \(i\) and an unassigned client set \(Y\) such that \(\frac{\text{open cost for }i+\text{net connection cost}}{\text{size of }Y}\) is minimized
- Net connection cost is defined as the total connection cost incurred when assigning the client set \(Y\) to facility \(i\), minus the potential cost savings from reassigning any clients who have already been assigned to another facility to facility \(i\) instead
While this algorithm is easy to understand, it cost exponential in time to pick the client set \(Y\). On the other hand, we can utilize the primal-dual property, and design another algorithm for the dual problem:
- Initialize opened facility set and assigned client set to be empty; and set “money” for each client to be zero
- While there exists clients who are unassigned:
- Increase clients’ “money” over time
- When an unassigned client’s “money” is enough for it to be connected to an opened facility, conect them
- When some clients’ money are “enough” to open a facility, open it
This dual approach is easier to be implemented.
Local search facility location algorithms
Local search is another effective approach which is also easy to implement. The algorithm runs as follows:
- Choose an arbitrary set of facilities to open
- Repeat the following actions:
- If there exists an unopened facility, such that opening it would decrease the total cost, then open it
- If there exists an opened facility, such that closing it would decrease the total cost, then close it
- If there exists an opened facility \(i\) and another unopened facility \(i'\), such that swapping them (i.e., closing \(i\) and opening \(i'\)) would decrease the total cost, then perform the swap
- If none of the above conditions are satisfied, terminate the procedure
Other algorithms
Furthermore, we tried dynamic programming, and tried different scaling parameters on connection cost versus opening cost, and did extensive experiments to validate that our methods outperform the baselines.
Experiments
The figure below shows evaluation of different methods on three real traces: MAWI, Wikipedia, and CAIDA. Total cost is calculated with various metrics, including hop count, latency, and sampled latency.
| Total cost with various metrics |
|---|
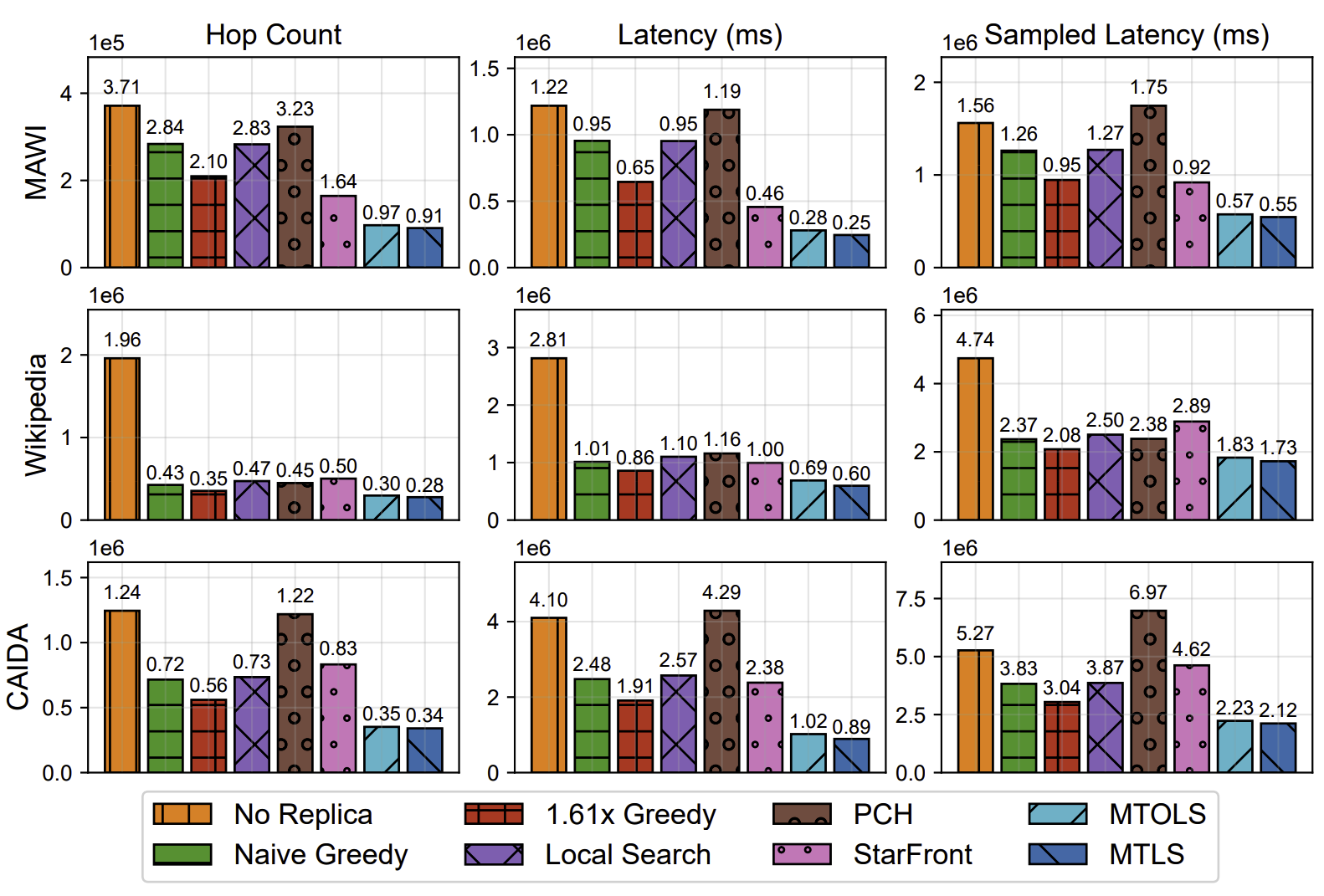 |
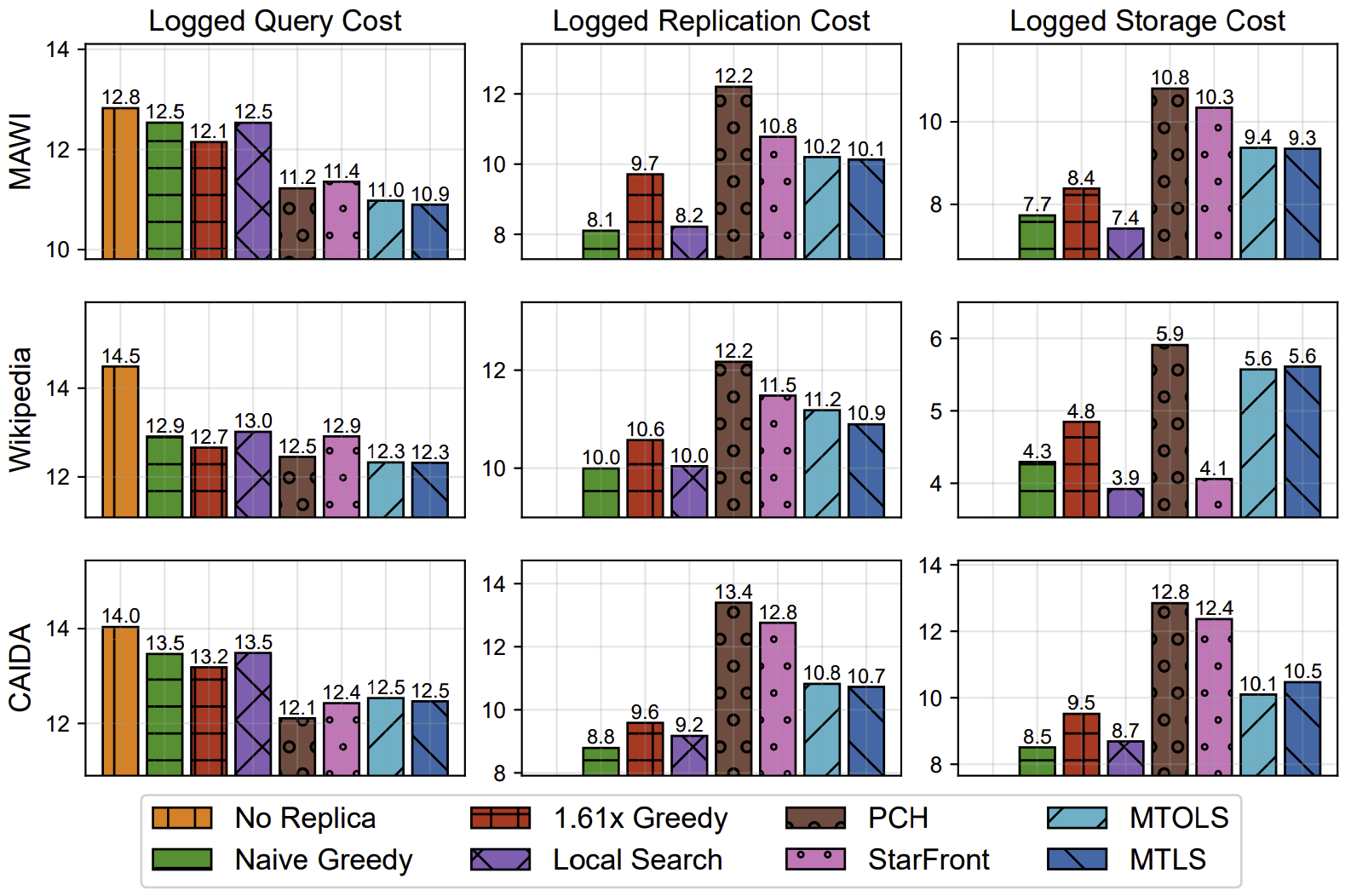
The following figure provides a breakdown of the total cost for the hop count metric, showing individual contributions of query cost, replication cost and storage cost.
| Breakdown of total cost (hop count metric) |
|---|
 |